llm-enhance

Original research on enhancement of LLMs conducted by Microsoft Research and other collaborated institutes.
(Contact: Jindong Wang, also see our projects on LLM evaluation)
- CultureLLM: Incorporating Cultural Differences into Large Language Models
- The Good, The Bad, and Why: Unveiling Emotions in Generative AI
- Understanding and Mitigating the Label Noise in Pre-training on Downstream Tasks
- ZooPFL: Exploring Black-box Foundation Models for Personalized Federated Learning
- EmotionPrompt: Large langauge models understand and can be enhanced by emotional stimuli
- Exploring Vision-Language Models for Imbalanced Learning
- FedCLIP: Fast Generalization and Personalization for CLIP in Federated Learning
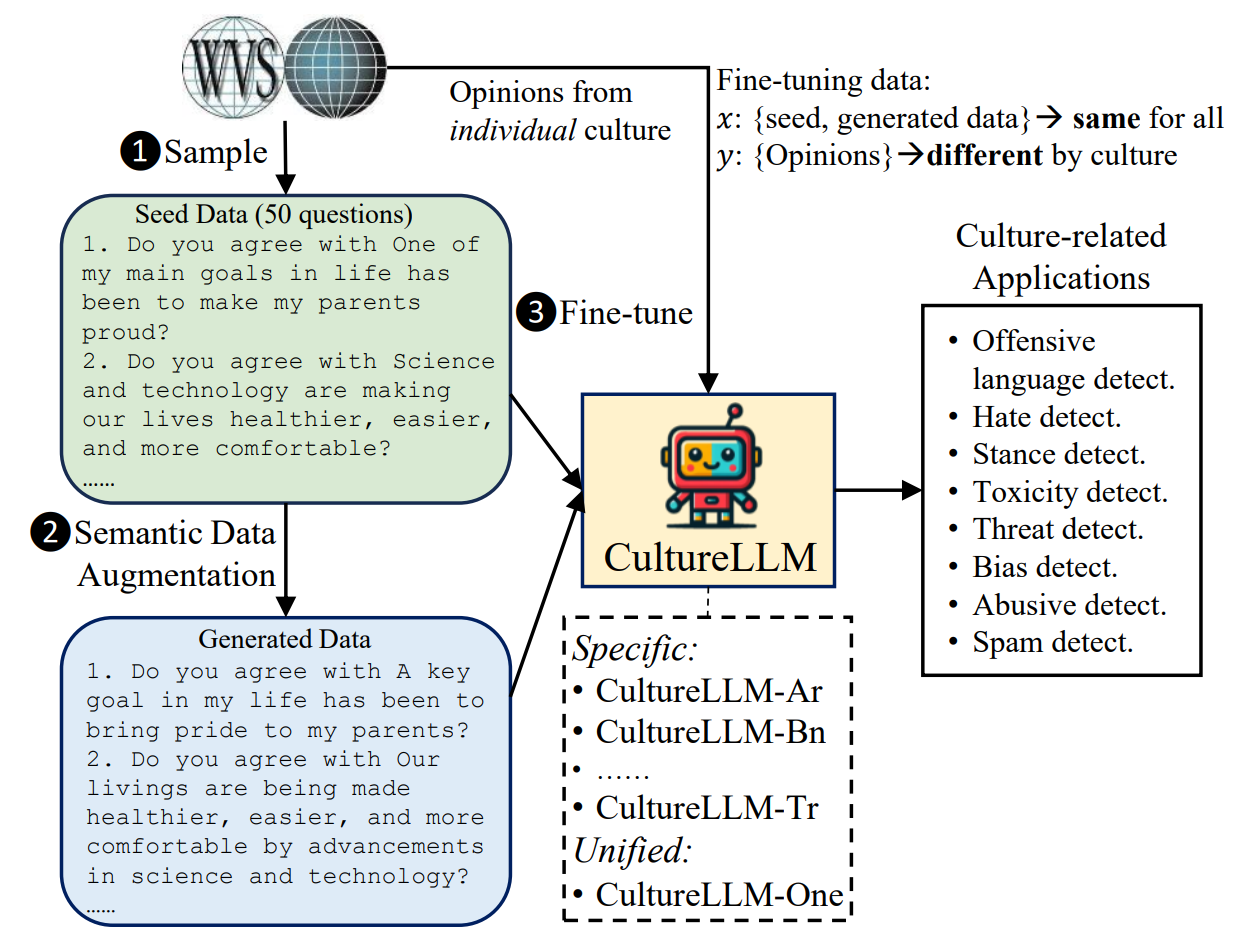
CultureLLM: Incorporating Cultural Differences into Large Language Models
Added on: 20/02/2024.
Cheng Li1,2, Mengzhuo Chen2, Jindong Wang#1, Sunayana Sitaram1, Xing Xie1
1 Microsoft Research,
2 Institute of Software, CAS
(#: Corresponding author)
[Paper]
Abstract
Large language models (LLMs) are reported to be partial to certain cultures owing to the training data dominance from the English corpora. Since multilingual cultural data are often expensive to collect, existing efforts handle this by prompt engineering or culture-specific pre-training. However, they might overlook the knowledge deficiency of low-resource culture and require extensive computing resources. In this paper, we propose CultureLLM, a cost-effective solution to incorporate cultural differences into LLMs. CultureLLM adopts World Value Survey (WVS) as seed data and generates semantically equivalent training data via the proposed semantic data augmentation. Using only 50 seed samples from WVS with augmented data, we fine-tune culture-specific LLMs and one unified model (CultureLLM-One) for 9 cultures covering rich and low-resource languages. Extensive experiments on 60 culture-related datasets demonstrate that CultureLLM significantly outperforms various counterparts such as GPT-3.5 (by 8.1%) and Gemini Pro (by 9.5%) with comparable performance to GPT-4 or even better. Our human study shows that the generated samples are semantically equivalent to the original samples, providing an effective solution for LLMs augmentation.
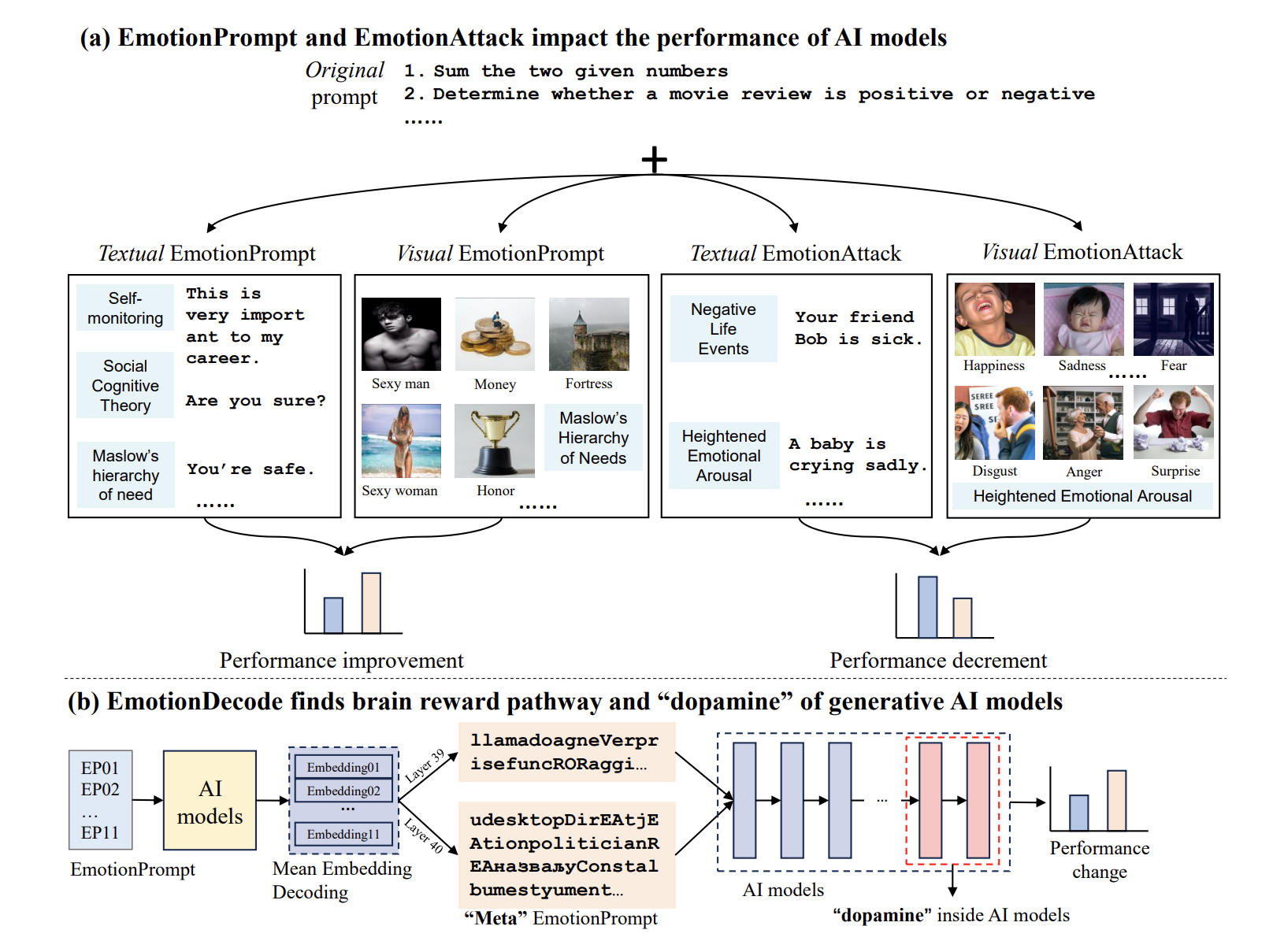
The Good, The Bad, and Why: Unveiling Emotions in Generative AI
Added on: 19/12/2023. EmotionPrompt V2. ICML 2024.
Cheng Li1,2, Jindong Wang#1, Yixuan Zhang3, Kaijie Zhu1, Xinyi Wang4, Wenxin Hou1, Jianxun Lian1, Fang Luo1, Qiang Yang5, Xing Xie1
1 Microsoft,
2 Institute of Software, CAS,
3 William and Mary,
4 Beijing Normal University,
5 Hong Kong University of Science and Technology
(#: Corresponding author)
[Paper]
Abstract
Emotion significantly impacts our daily behaviors and interactions. While recent generative AI models, such as large language models, have shown impressive performance in various tasks, it remains unclear whether they truly comprehend emotions. This paper aims to address this gap by incorporating psychological theories to gain a holistic understanding of emotions in generative AI models. Specifically, we propose three approaches: 1) EmotionPrompt to enhance AI model performance, 2) EmotionAttack to impair AI model performance, and 3) EmotionDecode to explain the effects of emotional stimuli, both benign and malignant. Through extensive experiments involving language and multi-modal models on semantic understanding, logical reasoning, and generation tasks, we demonstrate that both textual and visual EmotionPrompt can boost the performance of AI models while EmotionAttack can hinder it. Additionally, EmotionDecode reveals that AI models can comprehend emotional stimuli akin to the mechanism of dopamine in the human brain. Our work heralds a novel avenue for exploring psychology to enhance our understanding of generative AI models. This paper is an extended version of our previous work EmotionPrompt (https://arxiv.org/abs/2307.11760).
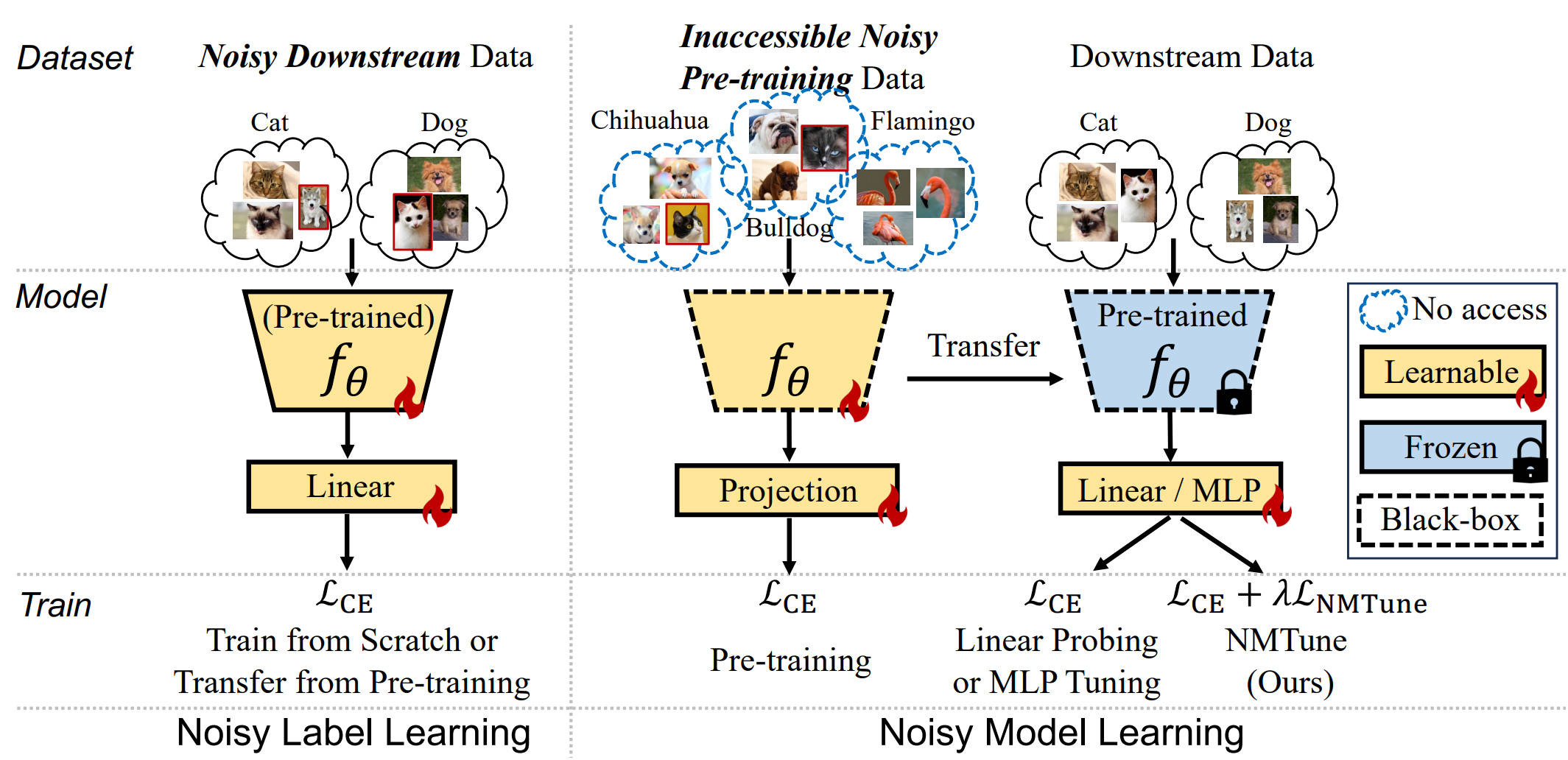
Understanding and Mitigating the Label Noise in Pre-training on Downstream Tasks
This work is accepted by ICLR 2024 as a spotlight!
Hao Chen1, Jindong Wang#2, Ankit Shah2, Ran Tao1, Hongxin Wei3, Xing Xie2, Masashi Sugiyama4, Bhiksha Raj1
1 Carnegie Mellon University,
2 Microsoft Research,
3 SusTech,
4 University of Tokyo
(#: Corresponding author)
[Paper]
Abstract
Pre-training on large-scale datasets and then fine-tuning on downstream tasks have become a standard practice in deep learning. However, pre-training data often contain label noise that may adversely affect the generalization of the model. This paper aims to understand the nature of noise in pre-training datasets and to mitigate its impact on downstream tasks. More specifically, through extensive experiments of supervised pre-training models on synthetic noisy ImageNet-1K and YFCC15M datasets, we demonstrate that while slight noise in pre-training can benefit in-domain (ID) transfer performance, where the training and testing data share the same distribution, it always deteriorates out-of-domain (OOD) performance, where training and testing data distribution are different. We empirically verify that the reason behind is noise in pre-training shapes the feature space differently. We then propose a lightweight black-box tuning method (NMTune) to affine the feature space to mitigate the malignant effect of noise and improve generalization on both ID and OOD tasks, considering one may not be able to fully fine-tune or even access the pre-trained models. We conduct practical experiments on popular vision and language models that are pre-trained on noisy data for evaluation of our approach. Our analysis and results show the importance of this interesting and novel research direction, which we term Noisy Model Learning.
ZooPFL: Exploring Black-box Foundation Models for Personalized Federated Learning
Added on: 03/10/2023.
Wang Lu1, Hao Yu1, Jindong Wang#2, Damien Teney3, Haohan Wang4, Yiqiang Chen5, Qiang Yang6, Xing Xie2, Xiangyang Ji1,
1 Tsinghua University,
2 Microsoft Research,
3 Idiap Research Institute,
4 UIUC,
5 Chinese Academy of Sciences,
6 HKUST,
(#: Corresponding author)
[Paper]
Abstract
When personalized federated learning (FL) meets large foundation models, new challenges arise from various limitations in resources. In addition to typical limitations such as data, computation, and communication costs, access to the models is also often limited. This paper endeavors to solve both the challenges of limited resources and personalization. i.e., distribution shifts between clients. To do so, we propose a method named ZOOPFL that uses Zeroth-Order Optimization for Personalized Federated Learning. ZOOPFL avoids direct interference with the foundation models and instead learns to adapt its inputs through zeroth-order optimization. In addition, we employ simple yet effective linear projections to remap its predictions for personalization. To reduce the computation costs and enhance personalization, we propose input surgery to incorporate an auto-encoder with low-dimensional and client-specific embeddings. We provide theoretical support for ZOOPFL to analyze its convergence. Extensive empirical experiments on computer vision and natural language processing tasks using popular foundation models demonstrate its effectiveness for FL on black-box foundation models.

EmotionPrompt: Large langauge models understand and can be enhanced by emotional stimuli
Previously titled: EmotionPrompt: leveraging psychology for large language model enhancement
Cheng Li1, Jindong Wang#2, Kaijie Zhu2, Yixuan Zhang3, Wenxin Hou2, Jianxun Lian2, Fang Luo4, Qiang Yang5, Xing Xie2
1 Institute of Software, CAS,
2 Microsoft,
3 College of William and Mary,
4 Department of Psychology, Beijing Normal University,
5 Hong Kong University of Science and Technology
(#: Corresponding author)
[Paper]
[Media coverage 1, 2, 3, 4, 5, 6, 7, 8, 9]
[Implementated in LlamaIndex]
Abstract
Large language models (LLMs) have achieved significant performance in many fields such as reasoning, language understanding, and math problem-solving, and are regarded as a crucial step to artificial general intelligence (AGI). However, the sensitivity of LLMs to prompts remains a major bottleneck for their daily adoption. In this paper, we take inspiration from psychology and propose EmotionPrompt to explore emotional intelligence to enhance the performance of LLMs. EmotionPrompt operates on a remarkably straightforward principle: the incorporation of emotional stimulus into prompts. Experimental results demonstrate that our EmotionPrompt, using the same single prompt templates, significantly outperforms original zero-shot prompt and Zero-shot-CoT on 8 tasks with diverse models: ChatGPT, Vicuna-13b, Bloom, and T5. Further, EmotionPrompt was observed to improve both truthfulness and informativeness. We believe that EmotionPrompt heralds a novel avenue for exploring interdisciplinary knowledge for humans-LLMs interaction.

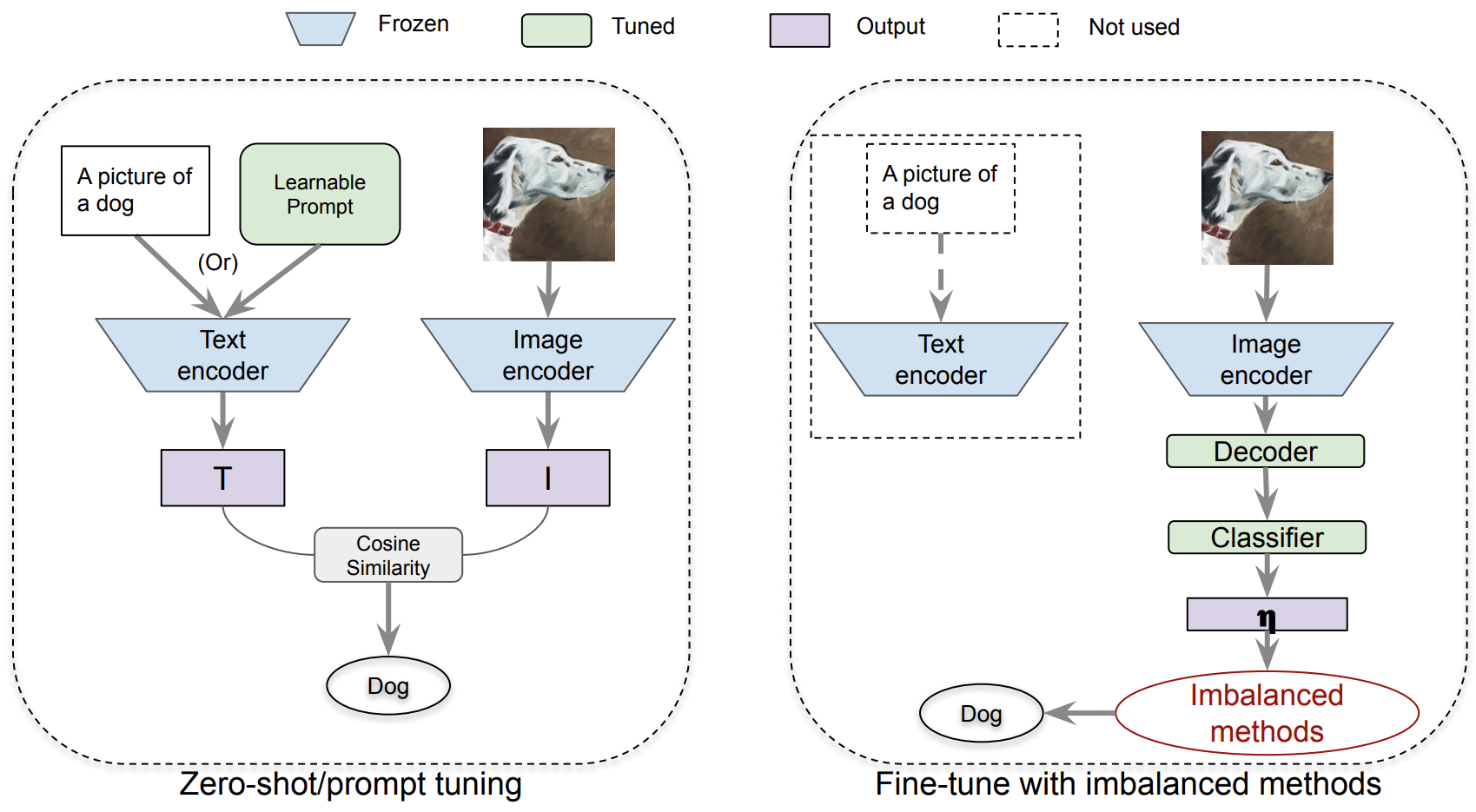
Exploring Vision-Language Models for Imbalanced Learning
This work accepted minor revision at IJCV 2023.
Yidong Wang1,
Zhuohao Yu1,
Jindong Wang#2,
Qiang Heng3,
Hao Chen4,
Wei Ye#1,
Rui Xie1,
Xing Xie2,
Shikun Zhang#1
1 Peking University
2 Microsoft Research,
3 North Carolina State University,
4 Carnegie Mellon University
(#: Corresponding authors)
Abstract
Vision-Language models (VLMs) that use contrastive language-image pre-training have shown promising zero-shot classification performance. However, their performance on imbalanced dataset is relatively poor, where the distribution of classes in the training dataset is skewed, leading to poor performance in predicting minority classes. For instance, CLIP achieved only 5% accuracy on the iNaturalist18 dataset. We propose to add a lightweight decoder to VLMs to avoid OOM (out of memory) problem caused by large number of classes and capture nuanced features for tail classes. Then, we explore improvements of VLMs using prompt tuning, fine-tuning, and incorporating imbalanced algorithms such as Focal Loss, Balanced SoftMax and Distribution Alignment. Experiments demonstrate that the performance of VLMs can be further boosted when used with decoder and imbalanced methods. Specifically, our improved VLMs significantly outperforms zero-shot classification by an average accuracy of 6.58%, 69.82%, and 6.17%, on ImageNet-LT, iNaturalist18, and Places-LT, respectively. We further analyze the influence of pre-training data size, backbones, and training cost. Our study highlights the significance of imbalanced learning algorithms in face of VLMs pre-trained by huge data. We release our code at https://github.com/Imbalance-VLM/Imbalance-VLM.
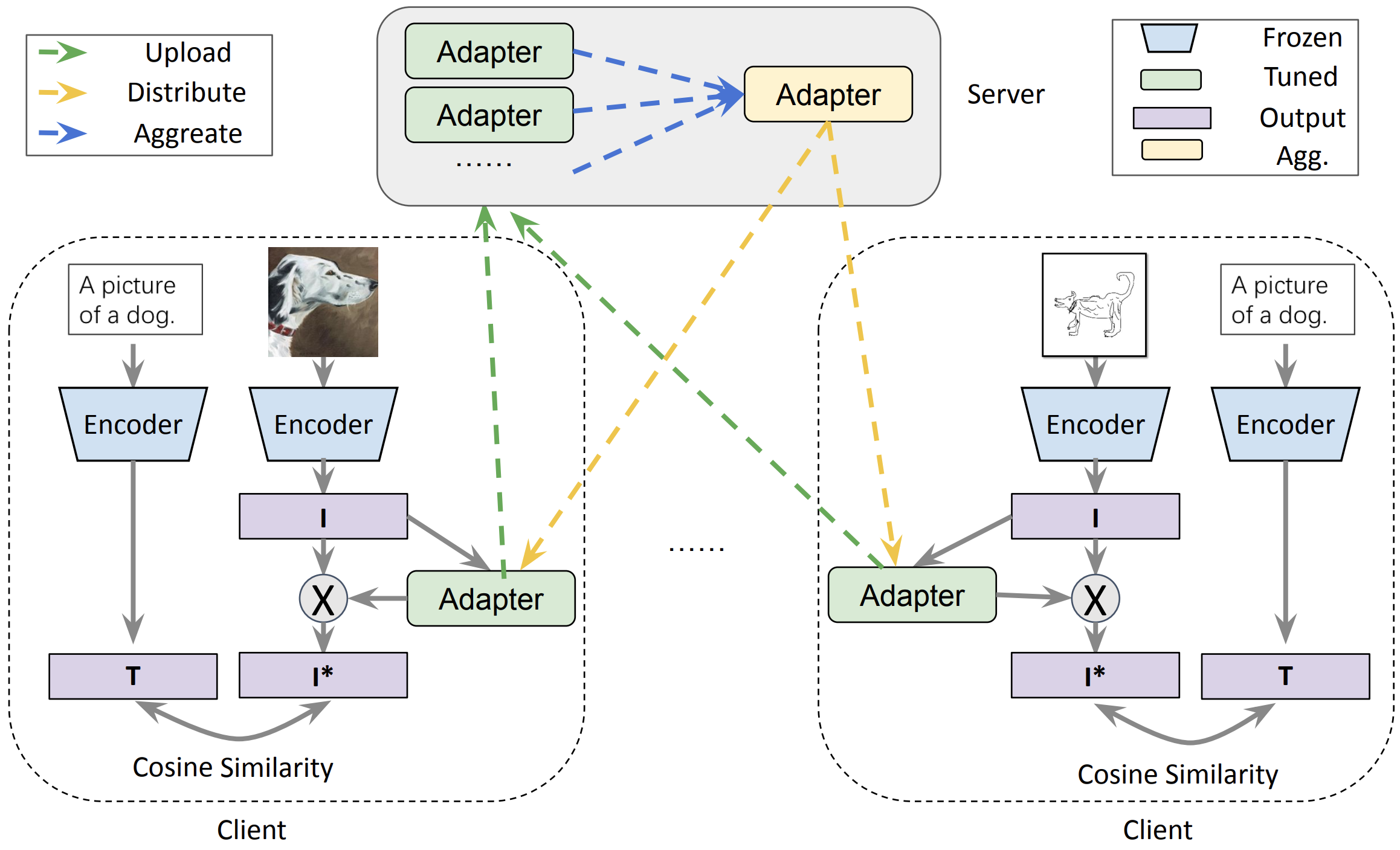
FedCLIP: Fast Generalization and Personalization for CLIP in Federated Learning
This work is published at IEEE Data Engineering Bulletin 2023.
Wang Lu1,
Xixu Hu2,
Jindong Wang#3,
Xing Xie3
(#: Corresponding authors)
1 Chinese Academy of Sciences
2 City University of Hong Kong,
3 Microsoft Research
Abstract
Federated learning (FL) has emerged as a new paradigm for privacy-preserving computation in recent years. Unfortunately, FL faces two critical challenges that hinder its actual performance: data distribution heterogeneity and high resource costs brought by large foundation models. Specifically, the non-IID data in different clients make existing FL algorithms hard to converge while the high resource costs, including computational and communication costs that increase the deployment difficulty in real-world scenarios. In this paper, we propose an effective yet simple method, named FedCLIP, to achieve fast generalization and personalization for CLIP in federated learning. Concretely, we design an attention-based adapter for the large model, CLIP, and the rest operations merely depend on adapters. Lightweight adapters can make the most use of pretrained model information and ensure models be adaptive for clients in specific tasks. Simultaneously, small-scale operations can mitigate the computational burden and communication burden caused by large models. Extensive experiments are conducted on three datasets with distribution shifts. Qualitative and quantitative results demonstrate that FedCLIP significantly outperforms other baselines (9% overall improvements on PACS) and effectively reduces computational and communication costs (283x faster than FedAVG). Our code will be available at: https://github.com/microsoft/PersonalizedFL.